Neural Information Retrieval
Retrieval of information: a user express their need in the form of a query and retrieval consists in ranking existing pieces of content or incorporating new responses from the obtained information.
Neural IR is the application of shallow or deep NN for IR tasks. Other NLP capabilities such as machine translation and named entity linking are not neural IR but could be used in an IR system.
IR systems must deal with short queries that may contain previously unseen vocabulary to match against documents that vary in length or find relevant documents that may contain large sections of irrelevant text.
Goal: Learn fundamentals of neural IR and traditional IR research
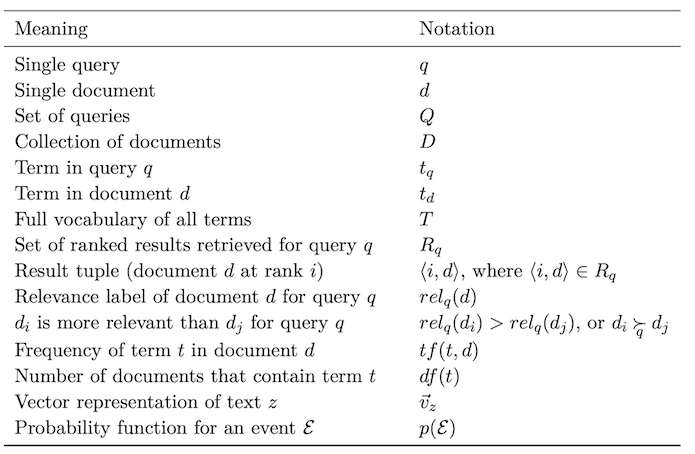
Fundamentals of text retrieval
Tasks
- ad hoc retrieval systems: ranking document retrieval
- question answering systems: ranking answers containing passages in response to a question
What is needed?
- Semantic understanding: careful → hot dog ≠ warm puppy
-
Robustness to rare inputs: support for infrequently searched-for documents and perform well in rare terms
query: “pekarovic land company” → exact match works for rare terms
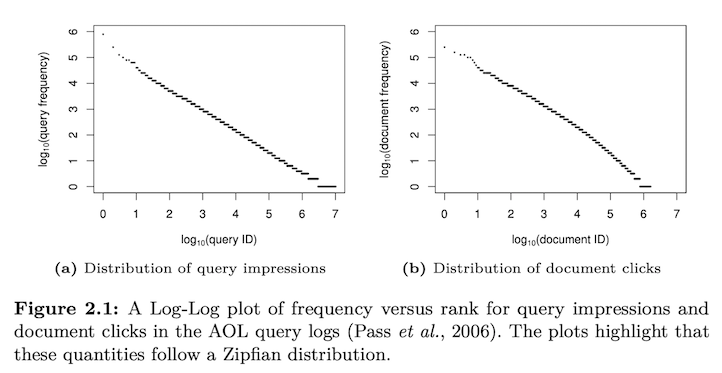
“Learning latent representations of text important for dealing with vocabulary mismatch, but exact matching is also important to deal with rare terms and intents.
-
Robustness to corpus variance: IR models perform on corpora whose distributions are different from the data that the model was trained on.
BM25: words “out of the box”
DNN: sensitive to distributional differences
- Robustness to variable length inputs: relevant documents may contain irrelevant sections and relevant content may either be localized or spread over multiple sections (in IR it is commonly used document length normalization)
- Robustness to errors in input: No IR system should assume error-free inputs, maybe use some error correction.
- Sensitivity to context: leverage implicit and explicit context information → query: weather (Seattle or London)
- Efficiency: It might be necessary to perform search with billions of documents
- Use telescoping: multi-tier architecture that different IR models prune a set of candidates (re-rank)
Metrics
IR metrics focus on rank-based evaluation of retrieved results vs ground truth information (manual judgments of implicit feedback from user behavior data)
-
Precision and recall
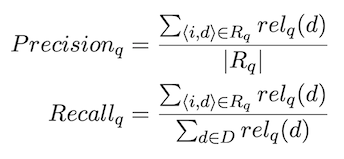
-
Mean reciprocal rank (MRR): averaged first relevant document over all queries
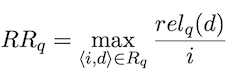
- Mean average precision (MAP): average precision for a ranked list of documents R
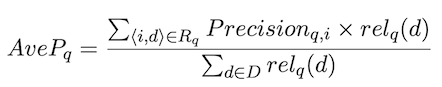
-
Normalized discounted cumulative gain (NDCG): used when graded relevance judgments are available for a query q, e.g. five-point scale.
Discounted cumulative gain:
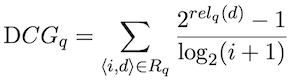
NDCG: assume the ideal DCG by getting the ideal rank order for the documents, up to rank k
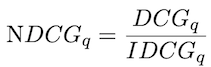
Traditional IR models
Important baselines for comparison
- BM25: consider the number of occurrence of each query term in the document (TF-IDF)
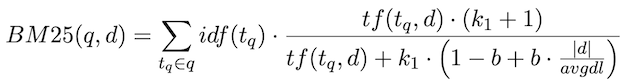
- Language modeling (LM): rank documents by the posterior probability
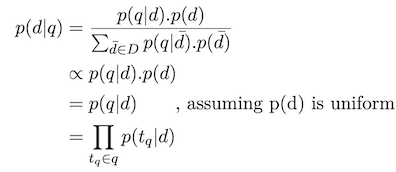
Using MLE:
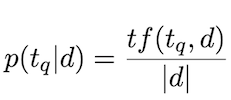
Adding smoothing:

- Translation models: alternative to LM, assume query q is being generated via a “translation” process from the document d
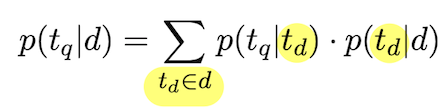
- Dependence model: consider proximity between query terms
ow and uw are the set of all contiguous n-grams or phrases
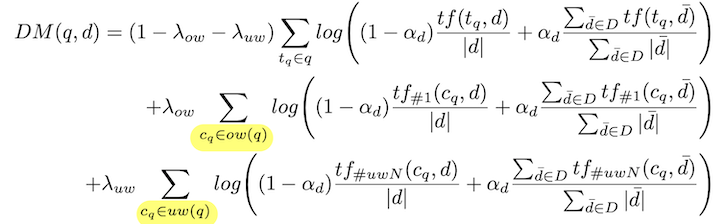
- Pseudo relevance feedback (PRF): a relevance model; additional round for retrieval
- R1: first round for retrieval
- Use R1 to expand terms and augment the query to retrieve R2 to the user
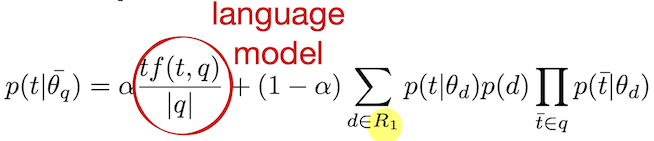
-
Neural approaches to IR: 1) query representation; 2) document representation; 3) estimating relevance
Traditionally shallow NN rely on hand-crafted features
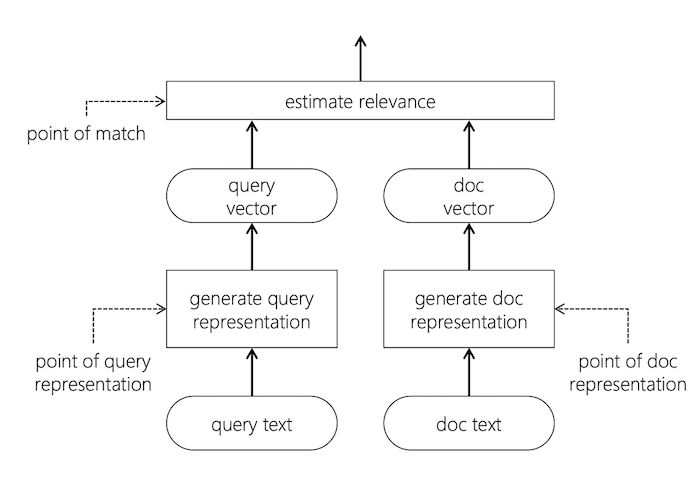
Traditionally DNN rely on embeddings
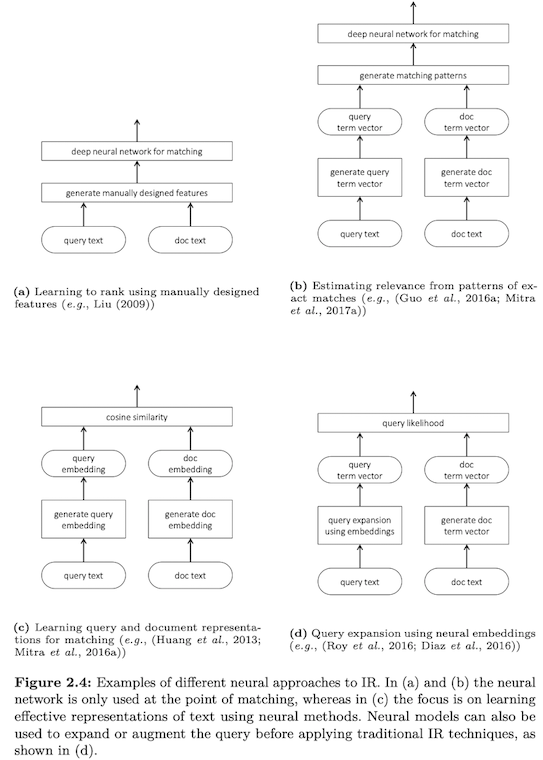
Unsupervised learning of term representations
Properties of compositionality help to select a term representation.
Local representation: one-hot encoding, terms are different, vocabulary size
Distributed representation: there’s a concept of similarity and embedding and latent space
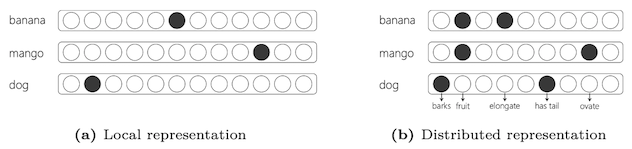
In distributed representation the choice of the feature is important. Makes a choice of which items are more similar.
Distributional hypothesis: terms that are used in similar context tend to be semantically similar, Harris 1954
Distributional semantics: a word is characterized by the company it keeps, Firth 1957
Notions of similarity
Is it a notion of relatedness between terms? Depends on the type of relationship we are interested in.
Is “Seattle” closer to “Sydney” or to “Seahawks”?
- Terms of similar type (typical): Seattle vs Sydney
- Terms co-occur in the same document (topical): Seattle vs Seahawks
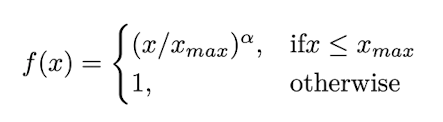
Many ways to categorize distributional features (neighboring terms, in-documents, etc) and different weighting schemes (e.g. TF-IDF)
We can get analogies such as:
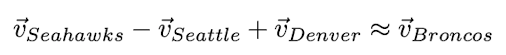
Latent feature spaces
Here some neural and non-neural latent space models
-
Latent Semantic Analysis (LSA)
Perform SVD on term-document matrix X to obtain its low-rank approximation. We select the k largest singular values to obtain a rank k approximation of X. For instance:
\[X_k=U_k\Sigma_kV_k^T\]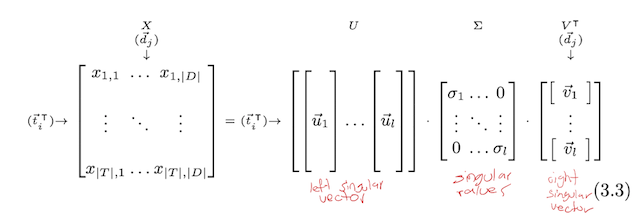
-
Probabilistic Latent Semantic Analysis (PLSA)
Learns low-dimensional representations by modeling their co-occurrence p( t, d ), where C are the latent topics.
\[p(t,d)=p(d)\sum_{c\in C}p(c|d)p(t|c)\]LDA: adds a Dirichlet prior
-
Neural term embedding
- predict term from its features
- learns dense low-dimensional representations by minimizing the prediction error based on the information bottleneck method
-
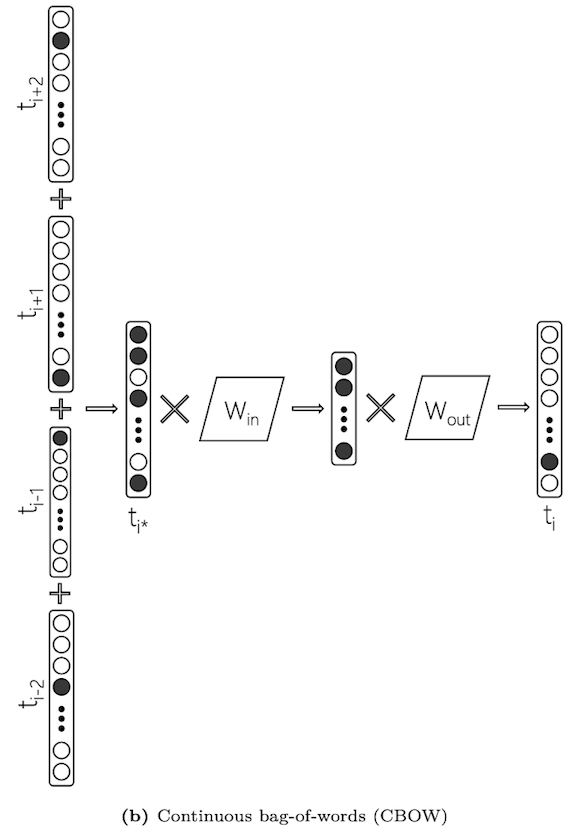
Word2vec (skip-gram / CBOW)
c: number of neighbours
S: set of all windows
Denominator is prohibitively costly
- Hierarchical softmax
- Negative sampling
W_{in} matrix embedding used and W_{out} is usually discarded after training. However, for IR applications, we can use both
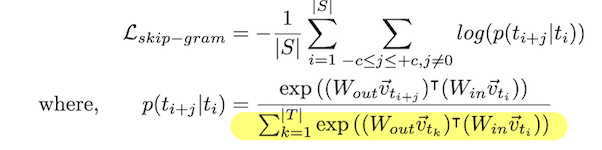
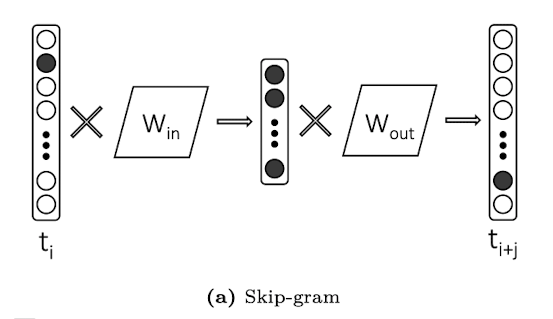
Skip-gram creates 2xc samples by individually pairing each neighbouring term with the middle term → slower to train
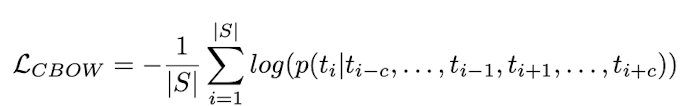
Encourage sparseness in the learnt representation, add the constraint (useful for term analogies):
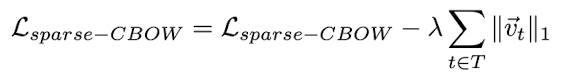
-
Glove
Shows that we can compute the cross-entropy error between the actual co-occurrence probability and the on predicted.
$L_{skip-gram}=\sum_{i=1}^{\mid{T}\mid}x_iH(\hat p(t_j\mid t_i), p(t_j\mid t_i))$
Two main changes compared with skip-gram model:
- replace cross-entropy error with squared error
- apply a saturation function
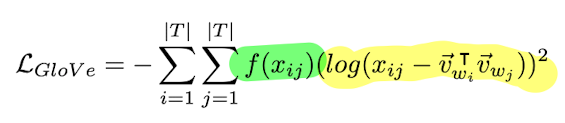
Final embeddings are the sum of IN and OUT vectors.
- Paragraph2vec
- Predict term given the id of a document
- Train term-document pairs to learn an embedding that is more aligned with a topical notion of the term-term similarity (appropriate for IR tasks)
- However, term-document relationship tens to be more sparse
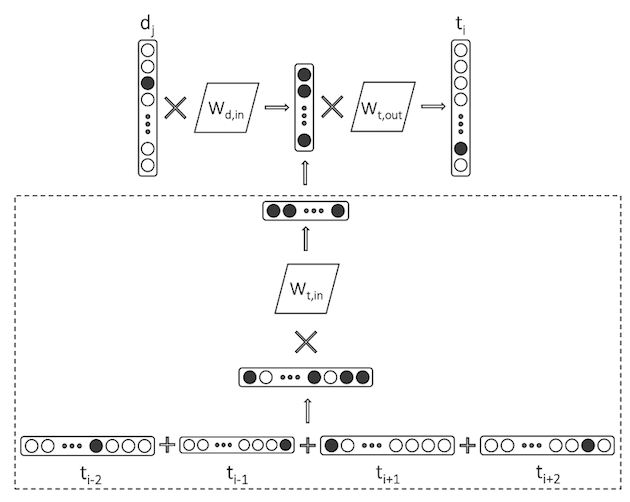
-
Term embeddings for IR
Term embeddings can be useful for inexact matching or for selecting additional terms for query expansion
Query-document matching
- Derive a dense vector representation for the query and document from the embeddings. Term embeddings can be aggregated most commonly used is AWE (average word embeddings)
- Query and document embeddings can be compared using a similarity metric
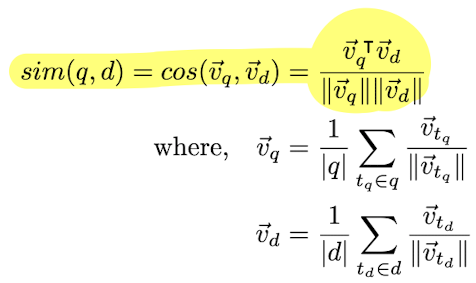
- Understand the notion of inter-term similarity
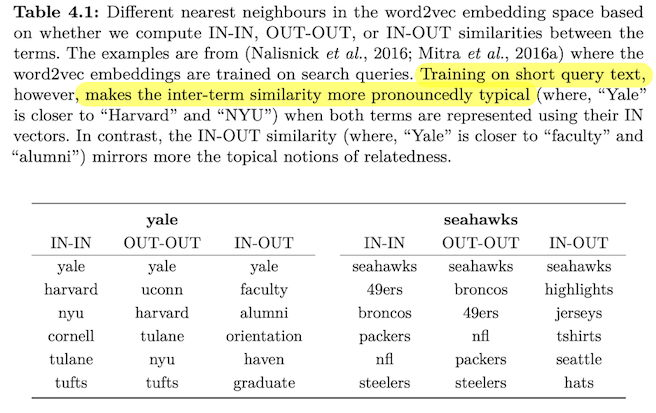
-
Dual Embedding Space Model (DESM)
Estimates the query-document relevance as follows
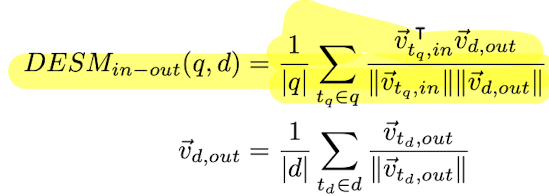
Instead of aggregating embeddings, we can incorporate term representations into existing IR models
-
Neural Translation Language Model (NTLM)
Uses the similarity between term embeddings as a measure for term-term translation probability
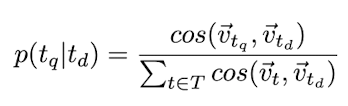
-
Generalized Language Model (GLM)
\[N_t:\text{set of nearest neighbours of term t}\]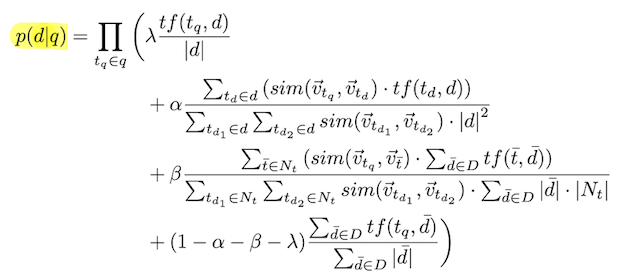
-
Other metrics for similarity
- Word Mover’s Distance (WMD): estimate similarity between pairs of documents by computing the minimum distance in the embedding space → “first document needs to travel to reach the terms in the second document”
-
Non-linear Word Transportation (NWT): incorporates a similar notion of distance.
solve optimization problem:
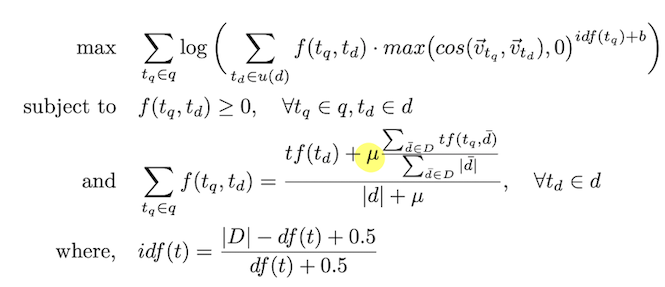
u(d): is the set of all unique terms in document d
-
Saliency weighted semantic network (SWSN): computing short-text similarity
motivation by BM25
\[S_s\text{: shorter sentence}\] \[S_l\text{: longer sentence}\]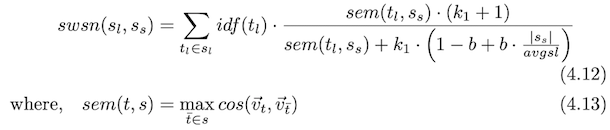
Errors by embedding based models and exact match models may be different and a combination is often preferred.
a) exact match for “Cambridge”
b) fails to detect “Oxford”
c) artificially injected the term “Cambridge”
explanation: exact match works for a and c (shouldn’t identify), embeddings work for a and c (no similarity found) but fails (embeddings) for b and exact match works best.

Query expansion
- Find good expansion candidates from a global vocabulary
- Retrieve documents using the expanded query
Compare every candidate term and then aggregate to get a relevance score
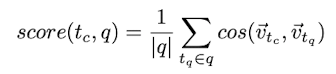
Term embeddings solely performs worse than pseudo-relevance feedback (PRF), but performs better when combined with PRF.
Local embeddings (embeddings trained in a query-specific corpus) are more useful for generating expansion terms
Supervised learning to rank
Learning to rank (LTR) uses training data to train towards an IR objective.
x → query-document pair as feature vector and learn a ranking model f
hand-crafted features can be categorized into three categories:
- Query-independent features (incoming link count and document length)
- Query-dependent features (BM25)
- Query-level features (query length)
neural models: learn from query and documents texts (can be combined with other features e.g. popularity)
- Feature learning
- Interaction-based representations
LTR approaches based on their training objective:
- Pointwise approach: numerical value associated with every query-document pair
- Pairwise approach: preference between pairs of documents with respect to individual queries $d_i >_q d_j$
- Listwise approach: optimize for a rank-based metric such as NDCG
mapping function f can be many models:
- SVMs
- Boosted Decision Trees
- Loss functions (see book for details)
- regression loss: estimate relevance label
- classification loss: multiclass classification
- contrastive loss: minimize distance between relevant pairs and increase distance between dissimilar items
- cross-entropy loss over documents: probability of ranking right document above over all other documents in a collection
- rank-net loss: rank document i higher than document j
- LambdaRank loss: weight rank-net with NDCG
- ListNet and ListMLE loss: probability of observing a particular order (distribution over all possible permutations)
Challenges:
- extreme classification: extremely large number of classes
- new loss functions suited for retrieval (research)
- require large amount of training data
Deep neural networks for IR
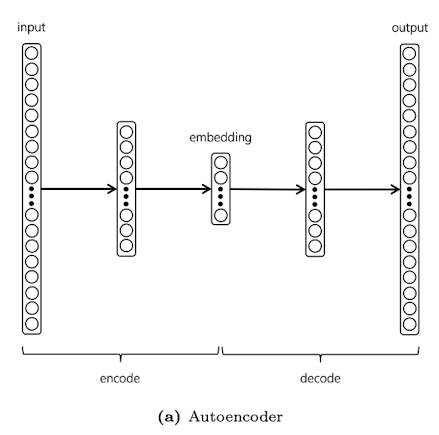
Autoencoders: optimized for reducing reconstruction errors
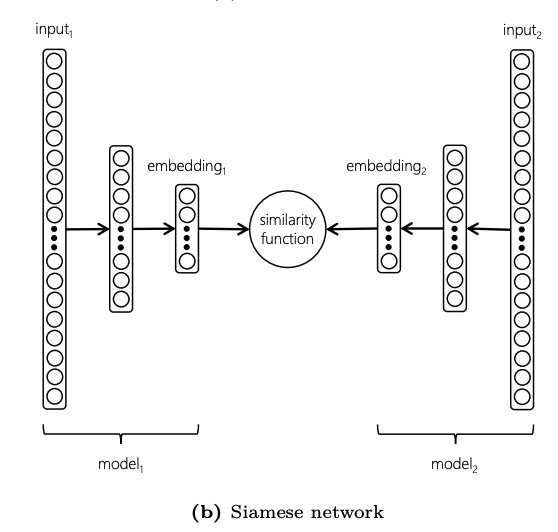
Siamese networks: optimized to better discriminate similar pairs from dissimilar ones
Data consists mainly of:
- Corpus of search queries
- Corpus of candidate documents
- Ground truth: implicit (clicks) or explicit (human relevance judgments)
For application consider the level of supervision based on the proportion of (un)labelled data:
- unsupervised
- semi-supervised
- fully-supervised
Ranking based on document length
- long documents: mixture of many topics and query matches may be spread
- short documents: vocabulary mismatches when performing similarity between pairs of texts
Document autoencoders
- Semantic Hashing
- Each document is a bag-of-terms and uses one hot representation for the terms.
- After training, the output is thresholded to generate a binary vector encoding for documents
- Given a search query → generate corresponding hash → retrieve relevant candidate documents
- Variational autoencoders
- Been explored but it might not be practical for IR tasks since it minimizes the document reconstruction error.
- Siamese architecture models seem to be more practical
Siamese networks
-
Deep Semantic Similarity Model (DSSM)
Two deep models that use cosine distance that minimizes cross-entropy loss
Used for short texts
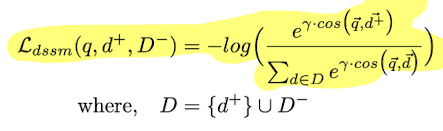
DSSM can use
- fully-connected layers
- Convolutional layers (CDSSM)
- RNNs
- Tree-structured networks
Notions of similarity for CDSSM
Similarity depends on the choice of paired data
query and document title pairs → topical
query prefix and suffix pairs → typical

Similarly other combinations tend to be better for query auto-completion or session-based personalization
Interaction-based networks
- Instead of representing query and document embeddings as single vectors (Siamese networks), we can individually compare different parts of the query with different parts of the document. Than aggregate these partial evidences of relevance.
- Useful for long documents
- Interaction: use an sliding window for both query and document text. Each instance of the query window is compare with each instance of the document window
- Typically implemented with a CNN
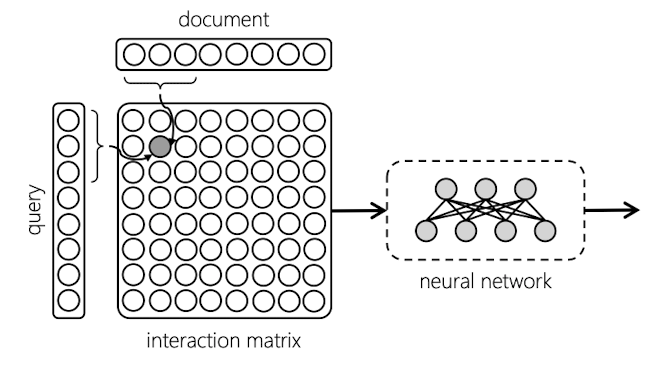
- Other works explore interaction matrix approach for short text matching and ranking long documents.
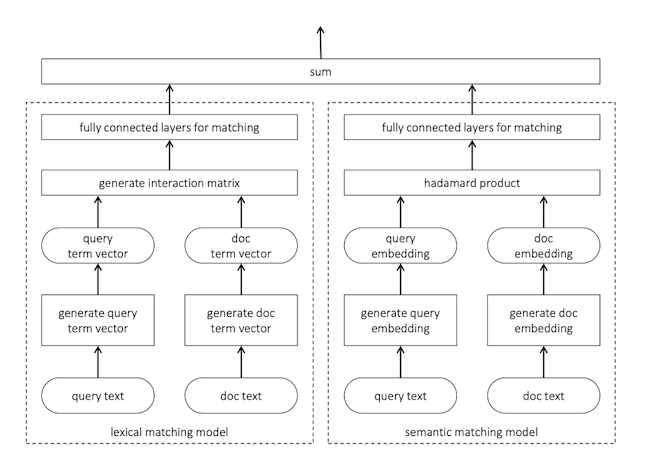
Lexical and semantic matching
Neural IR models perform poorly when rare terms are encountered
Query (exact match): “pekarovic land company”
“pekarovic” → rare term
-
it is easier to estimate relevance based on exact matches.
-
for a neural model it is harder to match or have a good representation
Query (semantic match): “what channel are the seahawks on today?”
maybe document doesn’t contain the word channel, but contains ESPN or SkySports
Model
- Use histogram-based features in the DNN to capture lexical notion of relevance
- Duet:
- leverage search data
- trains jointly lexical and semantic matches
- Neural models focusing in lexical matching have fewer parameters and can be trained under small data regimes
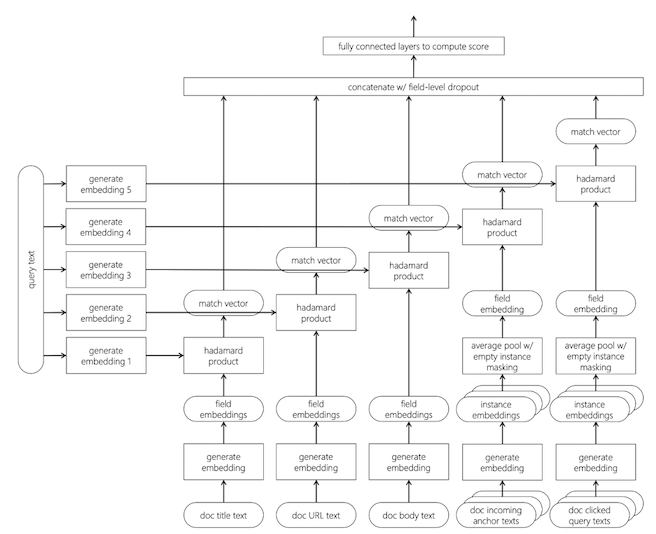
Matching with multiple document fields
Different documents fields may contain information relevant to different aspects of the query intent
Specially in search engines that index documents with different metadata such as hyperlinks, anchor texts, etc.
Future research problems for Neural IR
- Should the ideal IR model behave like a library that knows about everything in the Universe, or like a librarian who can effectively retrieve without memorizing the corpus?
- Future IR explorations using related areas
- reinforcement learning
- adversarial learning
- Some interesting applications
- query auto-completion
- query recommendation
- session modelling
- modeling diversity
- modeling user click behaviours
- proactive recommendations
- entity ranking
- multi-modal retrieval
- knowledge-based IR
- optimizing for for multiple IR tasks
- Some emerging scenarios
- conversation IR
- multi-modal retrieval
- one-shot learning
- Metrics for evaluation of document ranking systems
Some interesting links for embeddings
Model implementations